Applying AI to identify spatial clustering of pedestrian activity and street environment features
Yixuan Zhao & Hang Tian
Last compiled date: 08 December, 2022
1. Introduction
Active transportation modes, such as walking and cycling, and their
benefits to the enhancement of public health, quality of life, and urban
redevelopment, have attracted growing interest in recent years. The
design of “walkable” city is seen as a key method for mitigating
illnesses induced by a lack of exercise owing to automotive dependence.
Furthermore, creating vibrant street life has already been adopted as a
critical urban redevelopment strategy in the United States and many
other countries. While there have been many studies in the past that
have objectively and quantitatively examined the impact of the built
environment on street dynamism, a large number of studies have generally
focused on motorized modes of transportation and neglected studies on
pedestrians.
Understanding the underlying relationship between
spatial patterns of pedestrian activity, aggregation or dispersion, and
environmental features is critical. This helps city planners focus on
pedestrian safety. Today, advances in remote scanning technology are
used in intelligent transportation systems and public safety evacuation
research. Therefore, monitoring pedestrian activity and movement makes
it easier to understand complex collective behaviors in social systems.
Building on previous work, this study uses K-Mean and random forest
algorithms in machine learning to study the spatial patterns of
pedestrian numbers, built environment contributors, and spoilers on
eight high-traffic streets in Buffalo, New York. Pedestrian generators,
demographic characteristics, crime rates, and land-use combinations were
included as independent variables to investigate the impact of
neighborhood environmental characteristics on pedestrian willingness to
walk.
#Import packages we may use
knitr::opts_chunk$set(echo = TRUE, warning = F, message = F)
library(ggplot2)
suppressPackageStartupMessages(library(tidyverse))
library(animation)
suppressPackageStartupMessages(library(viridis))
library(naniar)
suppressPackageStartupMessages(library(sf))
suppressPackageStartupMessages(library(lubridate))
library(gganimate)
suppressPackageStartupMessages(library(transformr))
library(RColorBrewer)
suppressPackageStartupMessages(library(magick))
suppressPackageStartupMessages(library(randomForest))
library(fastDummies)2. Literature Review
There is already literature that discusses how to increase the liveliness of the street, dating back to Jacobs’ desire for variety at both the district and street level. Jacobs strongly promotes the intelligent use of street life to revitalize older neighborhoods, which has resulted in dense, mixed-use clusters, by examining a number of areas in New York City. Kevin Lynch conducts research via enhancing urban form and from the viewpoint of locals. studying urban perception to increase vigor on the streets Jan Gehl uses the qualities of space to welcome or repel, and White discovers that street design and building layout are essential to fostering a thriving street life. Rowley thinks that beautiful street designs and mixed-use structures promote street vitality and boost regional economy. The relationships between urban planning, pedestrian activity, and consumer behavior have also been researched. In order to increase walkability, American cities have taken a variety of measures, such as building housing in downtown areas, enhancing public transportation, and creating supportive community structures. A theoretical framework has been established by earlier research to explore the possibility of altering built environments to increase street dynamism. The researchers also mention the clustering of pedestrian activity and the connection between pedestrian activity and the built environment, to a certain extent. However, quantitative investigations of the link between community environment and pedestrian activity, and associated modeling tools, were only established in the early 2000s due to the absence of adequate spatial methodologies.
2.1. Built Environment and Pedestrians
Destination accessibility emphasizes the critical part that amenities play in luring pedestrians. According to Purciel et al. and Ewing et al., the amount of street furniture, the percentage of windows on the street, and the percentage of active street frontage are all aspects of the streetscape that are positively connected with pedestrian traffic. The definition of “pedestrian generator” in our model was developed with the help of destination accessibility and streetscape planning. According to studies on the relationship between the built environment and travel intention, “pedestrian generators” are places at each junction that have a high pedestrian foot traffic, such as eateries, museums, parks, etc.
2.2. Pedestrian demand modeling and random forest
So far, many models have been used to simulate and study pedestrian flow and crowd dynamics. Sathish & Venkatesh used a random forest approach to study the relationship between pedestrian, driver, and environmental characteristics with the aim of investigating factors that significantly influence the severity of pedestrian injuries caused by pedestrians. Yang et al. used machine learning methods such as support vector machines (SVM), ensemble decision trees (EDT), and k-nearest neighbors (KNN) to study the relationship between pedestrian survival and traffic accident scenarios. Sababa used a random forest model to study the relationship between pedestrian traffic accidents and the community environment. However, these research models are uninterpretable black box models, however, interpretable machine learning models are important, as data scientists need to prevent model bias and help decision makers understand how to use our models correctly. The more severe the scenarios, the more the models need to provide evidence of how they work and avoid mistakes. In addition, since most of the current research focuses on the relationship between traffic accidents and people, no one has used the random forest model to explain the relationship between people’s travel intention and community environment. Therefore, an interpretable random forest regression model based on SHAP was applied in this study to study the characteristics of streets that attract people to walk. SHAP is a “model interpretation” package developed in Python that can interpret the output of any machine learning model. Its name comes from SHapley Additive exPlanation. Inspired by cooperative game theory, SHAP builds an additive explanation model, and all features are regarded as “contributors”. For each predicted sample, the model produces a predicted value, and the SHAP value is the value assigned to each feature in that sample.
3. Case studies and Data Collection
3.1. Study area
Eight high-traffic streets in Buffalo were selected for the fieldwork for this study.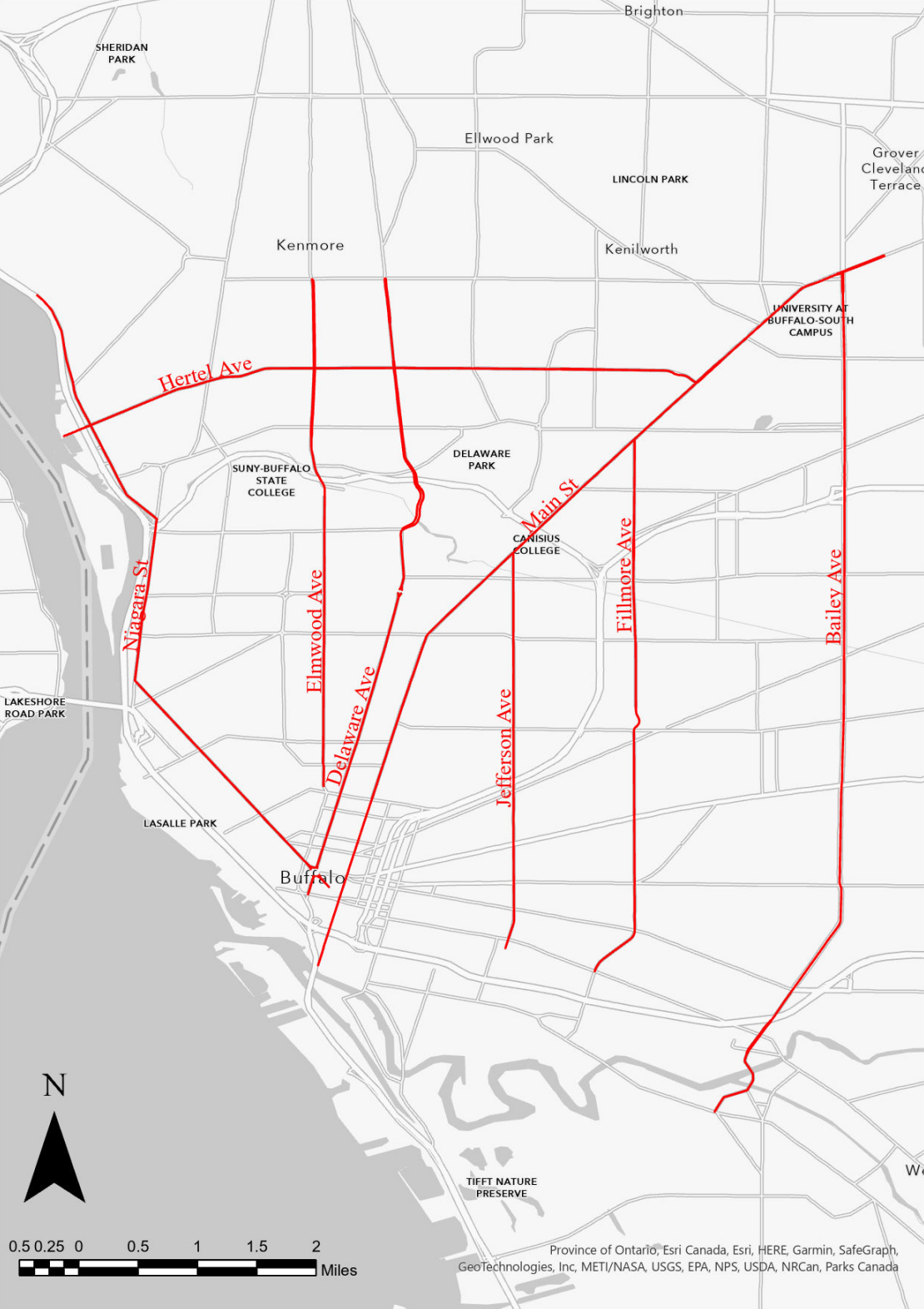
Figure 1
In Figure 1, the study area is depicted. These eight
streets were selected as the study’s locations because they act as the
city of Buffalo’s main thoroughfares. The Lower West Side, Downtown,
West Side, and North Buffalo are just a few of the most significant
areas that these boulevards—which are predominantly business
boulevards—pass through. According to the 2007 Great Places in America
Program of the American Planning Association, Elmwood Village on the
West Side was ranked as the third-best neighborhood. There are many
different restaurants, art galleries, museums, shops, cafés, and other
establishments. These “catalysts” encourage foot circulation to and from
local businesses, which dramatically accelerates neighborhood
development. One of the few vibrant sectors that fuels Buffalo’s economy
is the area surrounding the avenue. The public has a variety of parks,
schools, and public areas where they may congregate, walk, and play. As
a component of the Olmsted Park and Parkway network, these avenues cut
across Delaware Park’s western section. The park system offers a variety
of spots for people to unwind and take in the beauty, drawing both
locals and visitors.
3.2. Data Collection
The Greater Buffalo Niagara Regional Transit Commission’s (GBNRTC) Transportation Data Management System was used to gather information about traffic flow, pedestrian movement, geographical data at street crossings, and count dates and times for every intersection along the avenue. The study also gathered geographic data on “pedestrian generators,” such as restaurants and other eating establishments, supermarkets and markets, art galleries, event venues, office and retail complexes, trees, etc.; population makeup; crime statistics by type; traffic accidents; and land use portfolio with reference to Buffalo tax parcels. Shapefiles include geocoded tabular information on the locations of pedestrian generators. Every 15 minutes, eight hours every day, pedestrian counts are taken at each intersection of a road. 7am to 10am, 12pm to 2pm, and 3pm to 6pm are the designated times of the day. Few datasets contain information from January, the coldest month in Buffalo, even though data were gathered from May to August from 2009 to 2020. The study used pedestrian counts to gauge the vibrancy of the streets.
#This R chunck plots pedestrian distribution at observed time slots
data=read_csv('data/CCCCCCDep.csv')
#Only use useful part
data=data[,-c(4,7)]
#Create an sf class for plot
data.sf=st_as_sf(data,coords=c('Longitude','Latitude'))
data.sf=st_set_crs(data.sf,'WGS84')
data.sf=st_transform(data.sf,32618)
data.sf=data.sf[!duplicated(data.sf),]
#See how pedestrian number distributed
ggplot(data.sf)+
geom_boxplot(aes(,PedAve))+theme_bw()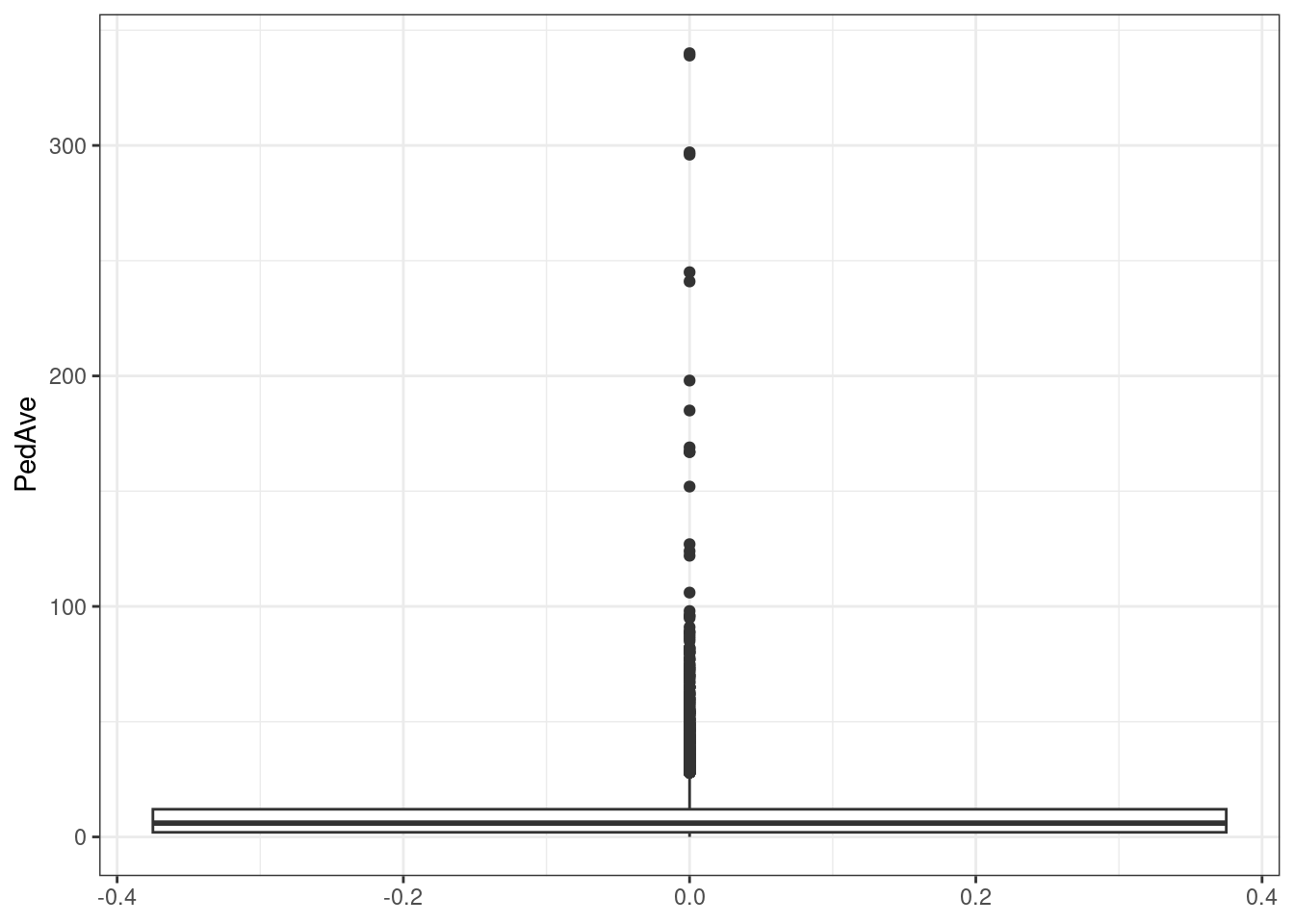
#Logged Pedestrain counts for a better color difference
data.sf$logged_Pedestrian=log2(data.sf$PedAve)
data.sf=data.sf%>%
mutate_if(is.numeric, function(x) ifelse(x<0,0,x))
c(min(unique(data.sf$logged_Pedestrian)),max(unique(data.sf$logged_Pedestrian)))## [1] 0.000000 8.409391data.sf$starttime=as.character(data.sf$starttime)
colnames(data.sf)[1]='intersection_id'
#Animated plot
plott=ggplot(data.sf,aes(color=logged_Pedestrian,size=logged_Pedestrian,stroke=1.2))+
geom_sf()+
scale_color_distiller(palette = "Spectral")+theme_bw()+
transition_states(starttime,transition_length=1,state_length = 5)+
labs(x='Logitude',y='Latitude',title=paste('Time :', '{closest_state}'))
#Run the anime!
animate(plott)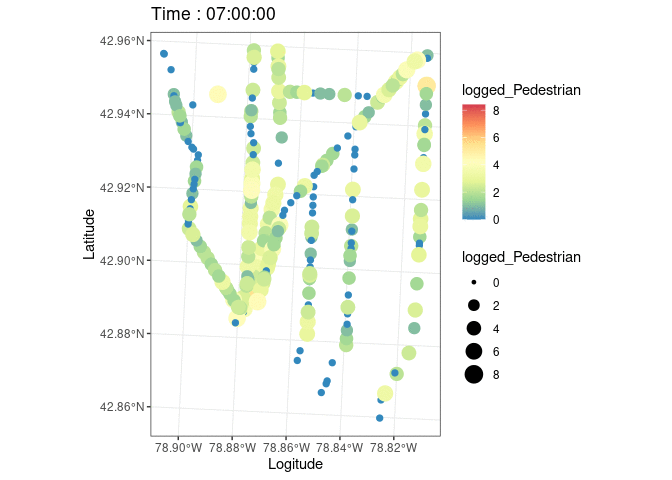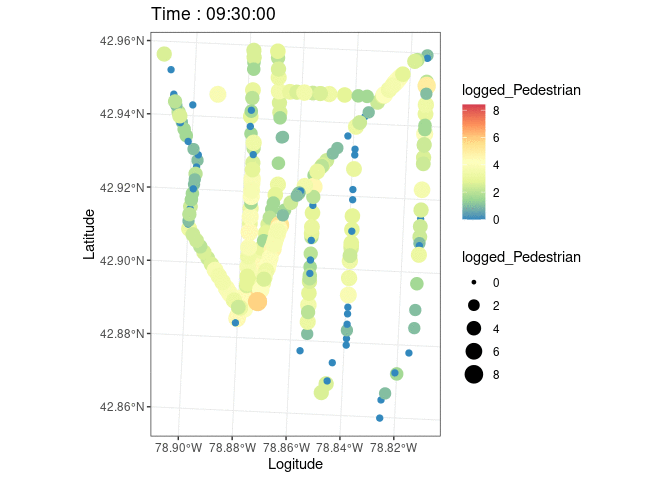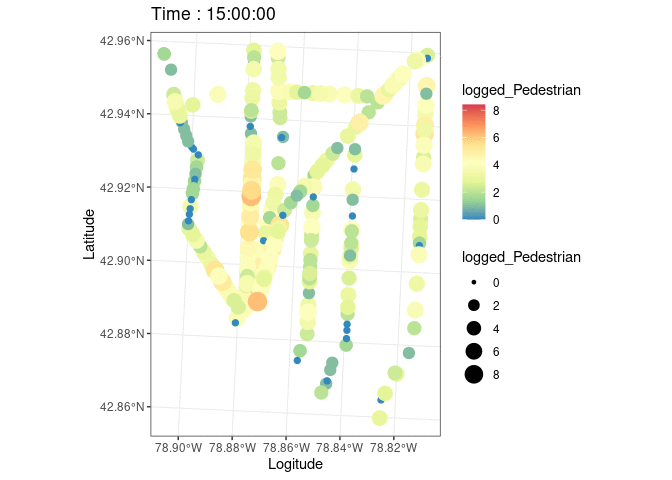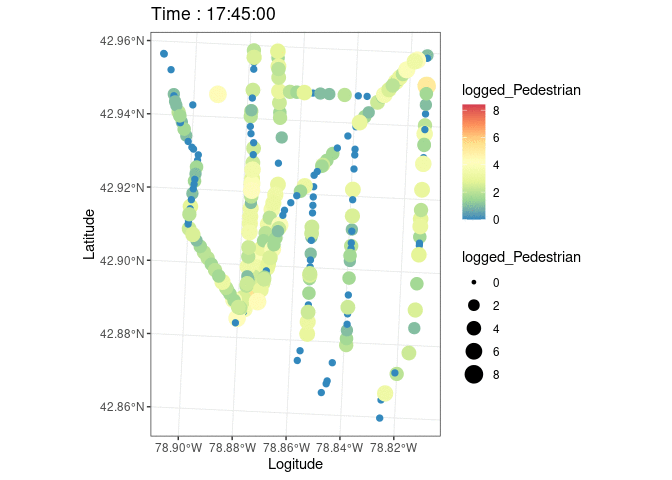
3.3. Data Processing
To determine the number of adjacent pedestrian generators, this study determines the radius of each intersection. 0.25 miles is frequently used as the acceptable walking distance in studies conducted in the United States. Walking distance and time are variable depending on the objective and demographic. In order to calculate the pedestrian generator, this study settled on a fair walking distance of 0.25 miles from each intersection. In this study, pedestrian generators were counted inside a network radius buffer of 0.25 miles that was created using network analyst at each intersection along the eight chosen roadways (shown in Figure 2). Population, crime, and traffic accidents are often used as objective measurements to evaluate the walkability of neighborhoods as one of the three-dimensional factors (density, variety, design). Social Explorer, ACS 2015 (5-year estimates), at the census block group level, provided information on the population composition in the area surrounding each junction. Data on crime, 311 sever and traffic accident are from the Buffalo Open Data period of 2009 to 2020. See Table 1 for detailed data information.
Table 1
data_des_table=read_csv('data/DATASET.csv')
knitr::kable(data_des_table)| Variable Name | Temporal Resolution | Spatial Resolution | Time Range | Unit | Definition |
|---|---|---|---|---|---|
| PedAve | Every 15 min with NAs | Points | 2009-2020 | num | Pedestrians per 15 minutes at each intersection |
| CarAve | Every 15 min with NAs | Points | 2009-2020 | num | Number of vehicles per 15 minutes at each intersection |
| Latitude | Every 15 min with NAs | Points | 2009-2020 | num | Y |
| Longitude | Every 15 min with NAs | Points | 2009-2020 | num | X |
| total_pop | Fixed | Within Buffer | ACS 2015 (5-year estimates), | num | Population within 0.25mi of each intersection |
| black | Fixed | Within Buffer | ACS 2015 (5-year estimates), | % | Percentage of African Americans within 0.25mi of each intersection |
| OccoRat | Fixed | Within Buffer | ACS 2015 (5-year estimates), | % | The proportion of houses occupied within 0.25mi of each intersection |
| Tree | Fixed | Within Buffer | 2020 | num | Number of trees on the inner road within 0.25mi of each intersection |
| Traffic | Fixed | Within Buffer | 2015 | num | The number of traffic accidents within 0.25mi of each intersection |
| Resi | Fixed | Within Buffer | 2015 | num | Number of residential land within 0.25mi of each intersection |
| Vaca | Fixed | Within Buffer | 2015 | num | The number of vacant land within 0.25mi of each intersection |
| Comm | Fixed | Within Buffer | 2015 | num | The number of commercial land within 0.25mi of each intersection |
| ComSev | Fixed | Within Buffer | 2015 | num | The number of community service land within 0.25mi of each intersection |
| BusStop | Fixed | Within Buffer | 2015 | num | Number of bus stops within 0.25mi of each intersection |
| Housing Violations | Sum through years | Within Buffer | 2009-2020 | num | Number of 311 Housing Violations within 0.25mi of each intersection |
| Police Issue | Sum through years | Within Buffer | 2009-2020 | num | Number of 311 Police Issues within 0.25mi of each intersection |
| Pot Hole | Sum through years | Within Buffer | 2009-2020 | num | Number of 311 Pot Holes within 0.25mi of each intersection |
| road walking environment | Sum through years | Within Buffer | 2009-2020 | num | The number of 311 road walking environments within 0.25mi of each intersection |
| Traffic problems | Sum through years | Within Buffer | 2009-2020 | num | The number of 311 Traffic problems within 0.25mi of each intersection |
| garbage problem | Sum through years | Within Buffer | 2009-2020 | num | The number of 311 garbage problems within 0.25mi of each intersection |
| Junk service problem | Sum through years | Within Buffer | 2009-2020 | num | The number of 311 Junk service problems within 0.25mi of each intersection |
| Neighborhood Environmental Issues | Sum through years | Within Buffer | 2009-2020 | num | Number of 311 Neighborhood Environmental Issues within 0.25mi of each intersection |
| Assault | Every 15 min time range, cumulated through years | Within Buffer | 2009-2020 | num | Number of Assaults within 0.25mi of each intersection |
| NovioCrime | Every 15 min time range, cumulated through years | Within Buffer | 2009-2020 | num | Number of NovioCrimes within 0.25mi of each intersection |
| Homicide | Every 15 min time range, cumulated through years | Within Buffer | 2009-2020 | num | Number of Homicides within 0.25mi of each intersection |
| Robbery | Every 15 min time range, cumulated through years | Within Buffer | 2009-2020 | num | The number of Robbery within 0.25mi of each intersection |
| SexualC | Every 15 min time range, cumulated through years | Within Buffer | 2009-2020 | num | Number of Sexual Crimes within 0.25mi of each intersection |
| ACCIDENT PROPERTY DAMAGE ONLY | Every 15 min time range, cumulated through years | Within Buffer | 2009-2020 | num | The number of ordinary traffic accidents within 0.25mi of each intersection |
| ACCIDENT SKYWAY/33/198 | Every 15 min time range, cumulated through years | Within Buffer | 2009-2020 | num | The number of traffic accidents on viaducts within 0.25mi of each intersection |
| ACCIDENT/INJURY | Every 15 min time range, cumulated through years | Within Buffer | 2009-2020 | num | The number of traffic accidents causing injury to people within 0.25mi of each intersection |
| Assault% | Fixed | Within Buffer | 2009-2020 | % | Assault crime rate (Assault crime sum through years / total_pop*100) within 0.25mi of each intersection |
| Homicide% | Fixed | Within Buffer | 2009-2020 | % | Homicide crime rate (Homicide sum through years / total_pop*100) within 0.25mi of each intersection |
| Robbery% | Fixed | Within Buffer | 2009-2020 | % | Robbery crime rate (Robbery sum through years / total_pop*100) within 0.25mi of each intersection |
| SexCrime% | Fixed | Within Buffer | 2009-2020 | % | SexCrime crime rate (SexCrime sum through years / total_pop*100) within 0.25mi of each intersection |
| NonviolentCrime% | Fixed | Within Buffer | 2009-2020 | % | NonviolentCrime crime rate (NonviolentCrime sum through years / total_pop*100) within 0.25mi of each intersection |
| Theft of Vehicle% | Fixed | Within Buffer | 2009-2020 | % | Theft of Vehicle crime rate (Theft of Vehicle sum through years / total_pop*100) within 0.25mi of each intersection |
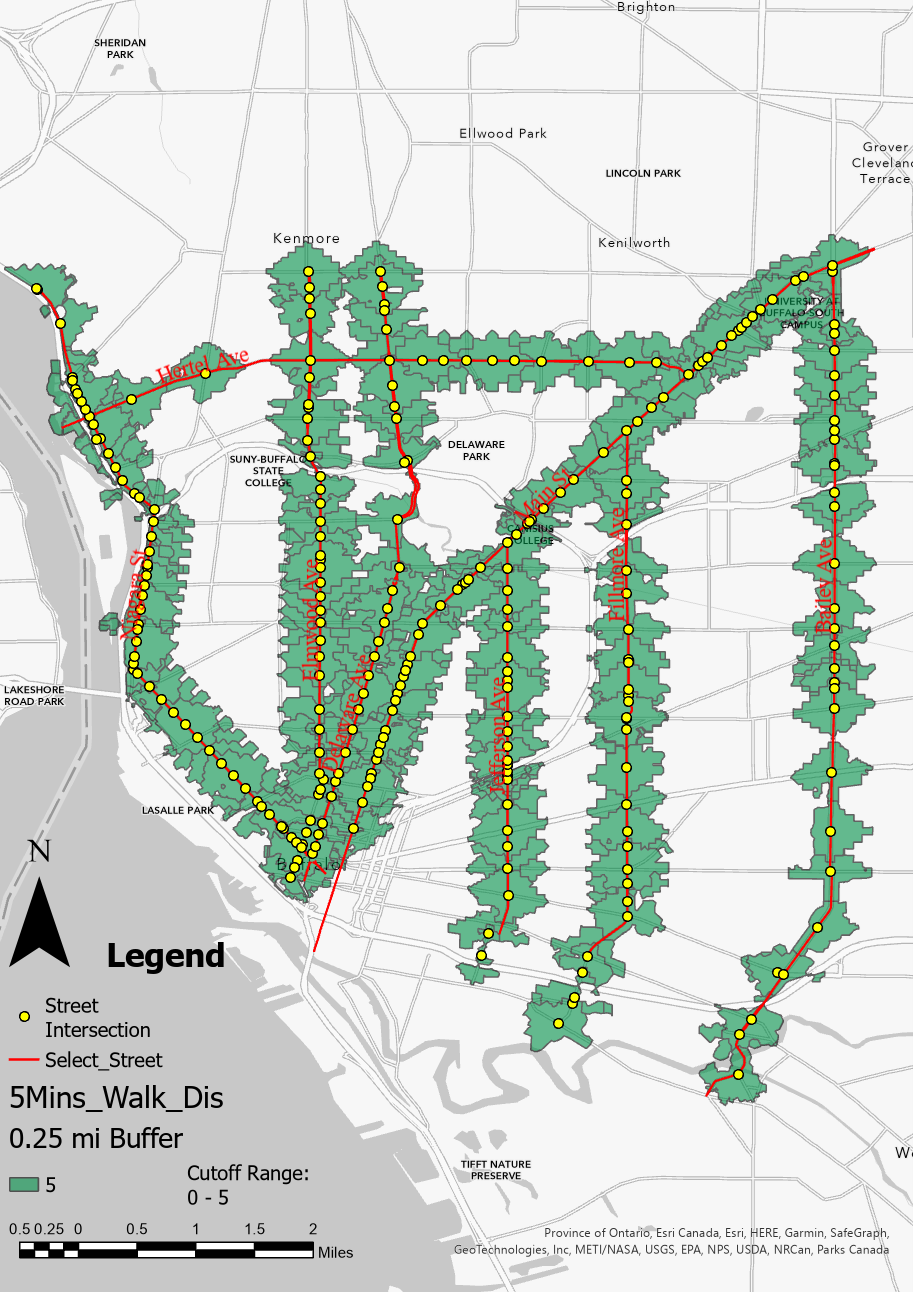
Figure 2
4. Random Forest Regression Model
#Read data table
table=read_csv('data/RunDataTest.csv')%>%as.data.frame()
#Check data availability
check=table%>%
miss_var_summary()
#Check if there are columns with NAs
unique(check$n_miss)## [1] 0#Keep the original data
model_table=table
colnames(model_table)## [1] "PedAve" "CarAve"
## [3] "Latitude" "Longitude"
## [5] "total_pop" "black"
## [7] "OccoRat" "Tree"
## [9] "Traffic" "Resi"
## [11] "Vaca" "Comm"
## [13] "ComSev" "BusStop"
## [15] "Housing Violations (Req_Serv)" "Police Issue (Req_Serv)"
## [17] "Pot Hole (Req_Serv)" "road walking environment"
## [19] "Traffic problems" "garbage problem"
## [21] "Junk service problem" "Neighborhood Environmental Issues"
## [23] "Assault" "NovioCrime"
## [25] "Homicide" "Robbery"
## [27] "SexualC" "ACCIDENT PROPERTY DAMAGE ONLY"
## [29] "ACCIDENT SKYWAY/33/198" "ACCIDENT/INJURY"
## [31] "Assault%" "Homicide%"
## [33] "Robbery%" "SexCrime%"
## [35] "NonviolentCrime%" "Theft of Vehicle%"#column names changing for model fitting
colnames(model_table)[15]='Housing_violations'
colnames(model_table)[16]='Police_Issue'
colnames(model_table)[17]='Pot_Hole'
colnames(model_table)[18]='Road_walking_environment'
colnames(model_table)[19]='Traffic_problems'
colnames(model_table)[20]='Garbage_problem'
colnames(model_table)[21]='Junk_service_problem'
colnames(model_table)[22]='Neighbourhood_environmental_issues'
colnames(model_table)[28]='Accident_Property_damage_only'
colnames(model_table)[29]='Accident_skyway'
colnames(model_table)[30]='Accident_injury'
colnames(model_table)[31]='Assault_percentage'
colnames(model_table)[32]='Homicide_percentage'
colnames(model_table)[33]='Robbery_percentage'
colnames(model_table)[34]='SexCrime_percentage'
colnames(model_table)[35]='NonviolentCrime_percentage'
colnames(model_table)[36]='Theft_of_Vehicles'
colnames(model_table)## [1] "PedAve" "CarAve"
## [3] "Latitude" "Longitude"
## [5] "total_pop" "black"
## [7] "OccoRat" "Tree"
## [9] "Traffic" "Resi"
## [11] "Vaca" "Comm"
## [13] "ComSev" "BusStop"
## [15] "Housing_violations" "Police_Issue"
## [17] "Pot_Hole" "Road_walking_environment"
## [19] "Traffic_problems" "Garbage_problem"
## [21] "Junk_service_problem" "Neighbourhood_environmental_issues"
## [23] "Assault" "NovioCrime"
## [25] "Homicide" "Robbery"
## [27] "SexualC" "Accident_Property_damage_only"
## [29] "Accident_skyway" "Accident_injury"
## [31] "Assault_percentage" "Homicide_percentage"
## [33] "Robbery_percentage" "SexCrime_percentage"
## [35] "NonviolentCrime_percentage" "Theft_of_Vehicles"#Model fitting
set.seed(1)
train_rows=sample(nrow(model_table),dim(model_table)[1]*0.8)
train_set=model_table[train_rows,]
test_set=model_table[-train_rows,]
test_x=test_set[,-1]
test_y=test_set[,1]
PedAve.rf <- randomForest(PedAve ~ .,
data = train_set,
importance = TRUE,
ntree=400,
xtest=test_x,
ytest=test_y,
keep.forest=TRUE)
#Model evaluation
print(PedAve.rf)##
## Call:
## randomForest(formula = PedAve ~ ., data = train_set, importance = TRUE, ntree = 400, xtest = test_x, ytest = test_y, keep.forest = TRUE)
## Type of random forest: regression
## Number of trees: 400
## No. of variables tried at each split: 11
##
## Mean of squared residuals: 29.0577
## % Var explained: 75.86
## Test set MSE: 22.69
## % Var explained: 74.29plot(PedAve.rf)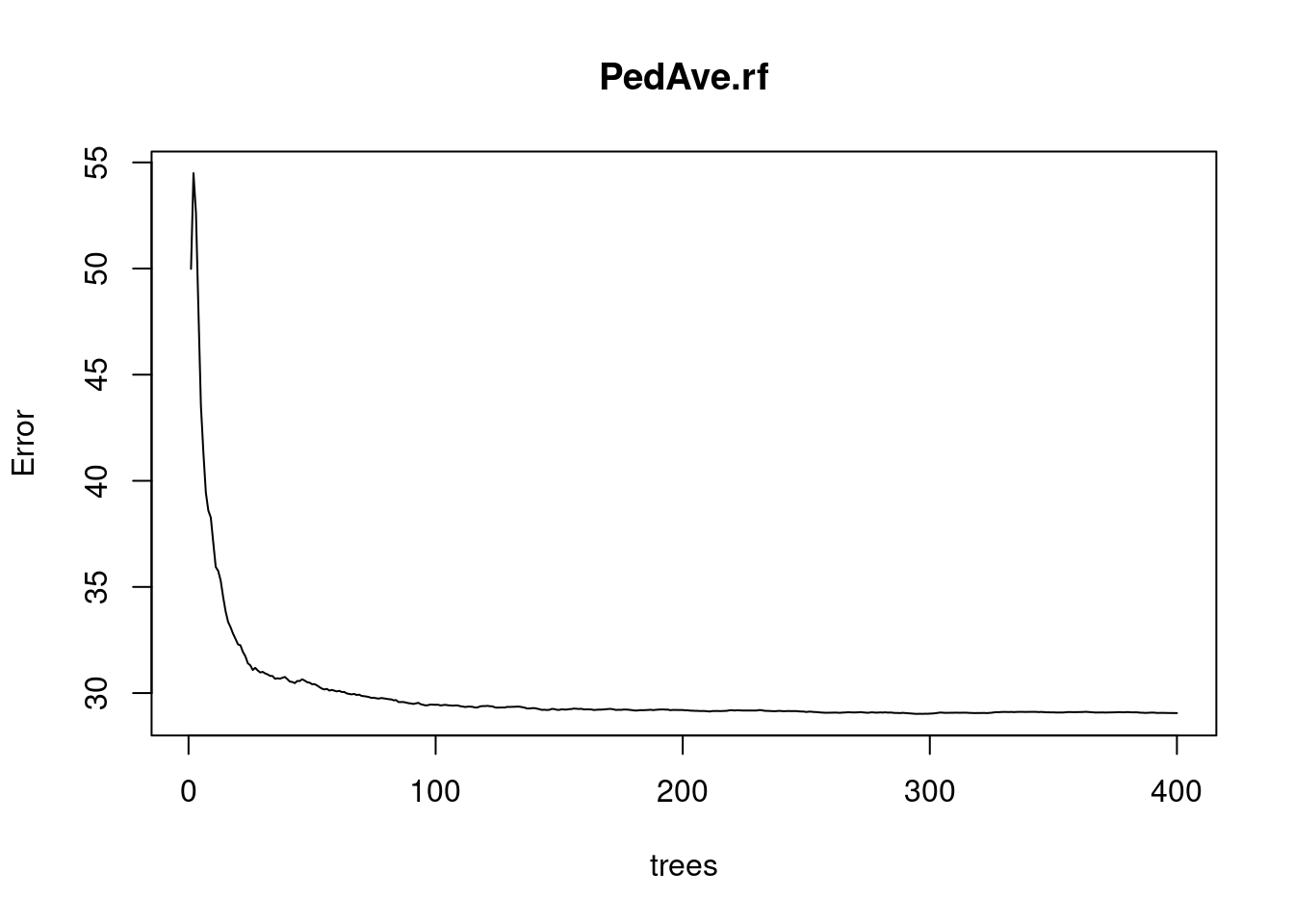
#30 most important attributes
# varImpPlot(PedAve.rf, n.var = min(30, nrow(PedAve.rf$importance)),
# main = 'Top 30 - variable importance')
knitr::include_graphics('img/Importance.png')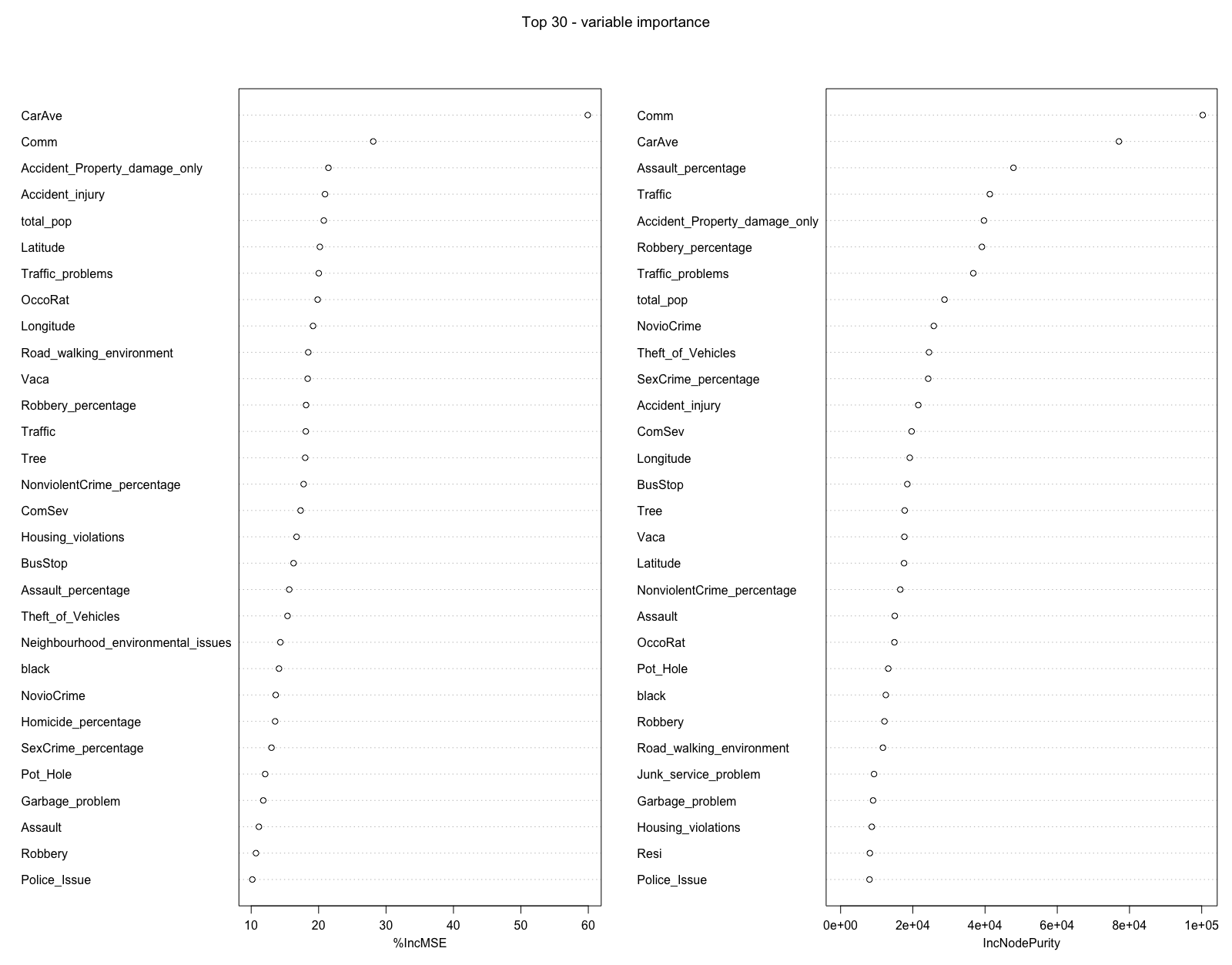
This research also uses the SHAP machine learning model to explain the model at the end. The generation and verification of the model is carried out in Python, because Python provides a better API to operate the SHAP explanation model. The generated results are shown in Figure 3.
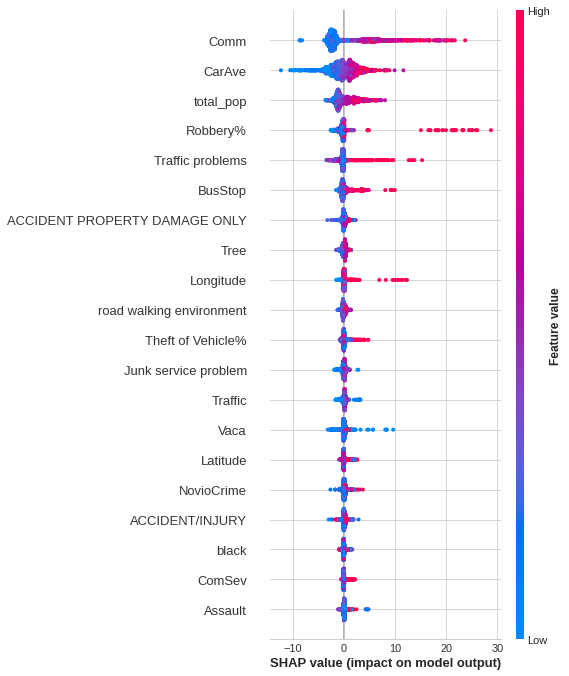
Figure 3
5. Discussion and Conclusion
After testing, our model can accurately predict 75%+ of the test data. From the data point of view, our research proves that the street environment has an impact on the number of pedestrians on the street. Among them, business activities, crime rate and traffic quality have a greater impact on the number of pedestrians on the street. According to variable importance, the top 10 variables that are highly correlated with the number of pedestrians on the street are the number of commercial areas, the number of motor vehicles on the street, the crime rate of assault, the number of traffic accidents, the rate of robbery crime, the quality of traffic, the total number of Population, nonviolent crime, and vehicle theft. After that, we used SHAP to further explain the relationship between the variables in the model and the number of pedestrians. The study found that when there are many pedestrians near the street, there are usually more commercial activities, resident population, traffic problems, number of bus stops and Robbery crime rate. This is in line with findings from previous studies, which found that commercial activities are more likely to attract some people to drive and walk nearby, and that when large numbers of people gather in certain locations, they often cause serious traffic problems. In addition, some research on crime has also shown that robberies are more likely to occur where pedestrians congregate, because more pedestrians provide more targets for crime, and dense crowds can interfere with law enforcement agencies’ efforts to catch criminals . The study contributes to understanding the spatial patterns of pedestrian activity and the geographically changing relationship between the built environment and pedestrian numbers. It is hoped that this research will guide policymakers and urban planners by transforming the built environment to introduce street dynamism, thereby improving the quality of life in the community.
6.Contribute:
Yixuan Zhao: Research design, literature review, data collection and cleaning, Python data analysis, text editing. Hang Tian: data processing, data visualization, website development, R data analysis, text editing.